





Google Colaboratory를 이용한 머신 러닝
안녕하세요. 오늘은 머신 러닝 환경 구축을 좀 더 쉽고, 더 좋은 환경을 다름 아닌 무료로 사용해보는 시간을 가져보겠습니다.
머신 러닝을 내 PC의 환경에서 구축하는 일이란, 사실 쉽지 않습니다. 제가 꽤 오래 전에 TensorFlow를 GPU 환경에서 돌릴 수 있도록 Python의 Virtualenv에서 TensorFlow를 구축하는 방법을 올렸었는데요.
리눅스를 설치하고, Python을 설치하고, 또 그에 필요한 TensorFlow, Virtualenv를 구축하고 나면 이제는 GPU 드라이버를 설치해야 하는데, 오류도 많이 나고, 여간 쉽지 않은 과정들이 벌어지게 됩니다.
만약, 여러분들이 정말로 고급 장비를 가지고, 이를 테면 Tesla 8개를 SLI로 묶는다던지, 이렇게 한다면 위 과정을 정말로 어렵게 어렵게 구축을 하셔야 할 것입니다. 하지만 나는 그냥 간단한 머신 러닝만 연습하고 싶고, GPU도 너무 안좋아서 클라우드를 이용하고 있다. 라고 하신다면, 오늘 Google Colaboratory를 통해서 쉽게 머신 러닝을 할 수 있는 방법을 꼭 터득해가셨으면 좋겠습니다.
Google Colaboratory
Google Colab이라고 하는 이 솔루션은 Google이 사내에서 사용하고 있는 Jupyter를 일컫는 말입니다. 과거에는 Google이 사내에서 직원들만 사용하였다가 이제는 일반인들도 사용할 수 있도록 공개한 것인데요. Google 계정을 사용하고 있다면 누구든지 우리는 이 환경을 사용하여 Python 환경을 만들 수가 있습니다.
먼저 Google에 로그인하여 Google 드라이브로 접속하도록 하겠습니다.
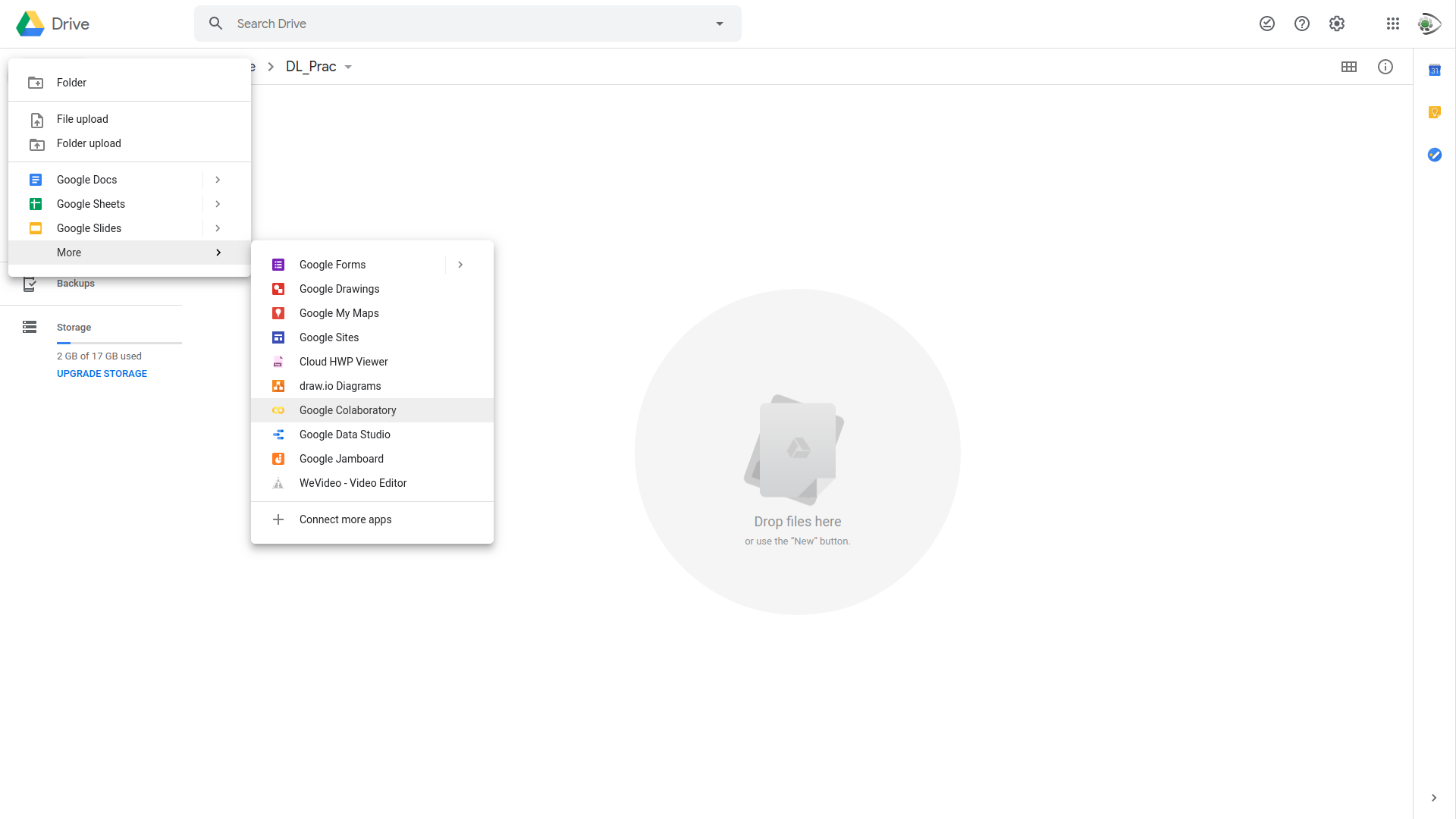
그런 다음, 왼쪽 상단의 New 버튼을 클릭하셔서 More에 들어가게 되면, Google Colaboratory라는 문서를 새로이 만드실 수 있는 버튼을 만나게 됩니다. 만약 이 버튼이 없다면 Connect more apps에 들어가봅니다.

상단의 검색에서 "Colab"이라는 단어를 검색하시게 되면, Google Colaboratory가 나타날 것입니다. 이를 클릭하시면 Google Colaboratory가 여러분들의 드라이브에 활성화 될 것입니다.
그러면 새로운 ipynb(Jupyter Notebook) 파일이 만들어지고, 여러분들은 이제 Google Colaboratory라는 가상의 환경에서 Python으로 머신 러닝을 할 수 있습니다.
Install Packages
그런데, 한 가지 의문점이 있습니다. 데이터 처리를 하다보면, 그 유형에 따라 내가 원하는 패키지를 설치하고 싶을 때가 있습니다. 일반 리눅스에서는 터미널 창을 열어서 pip 명령어로 설치했지만 Colab에서는 그러한 터미널 환경을 주지 않습니다. 이럴 때는 어떻게 해야 할까요?
Jupyter를 자주 사용하시는 분들이라면, Jupyter Notebook에서 대부분 패키지를 설치해봤을 것입니다. 하지만 처음이신 분들은 이러한 환경이 있음을 매우 생소하게 느낄 것인데, 실제로 Jupyter Notebook 내에서도 운영체제의 커맨드를 사용할 수 있는 방법이 있습니다.
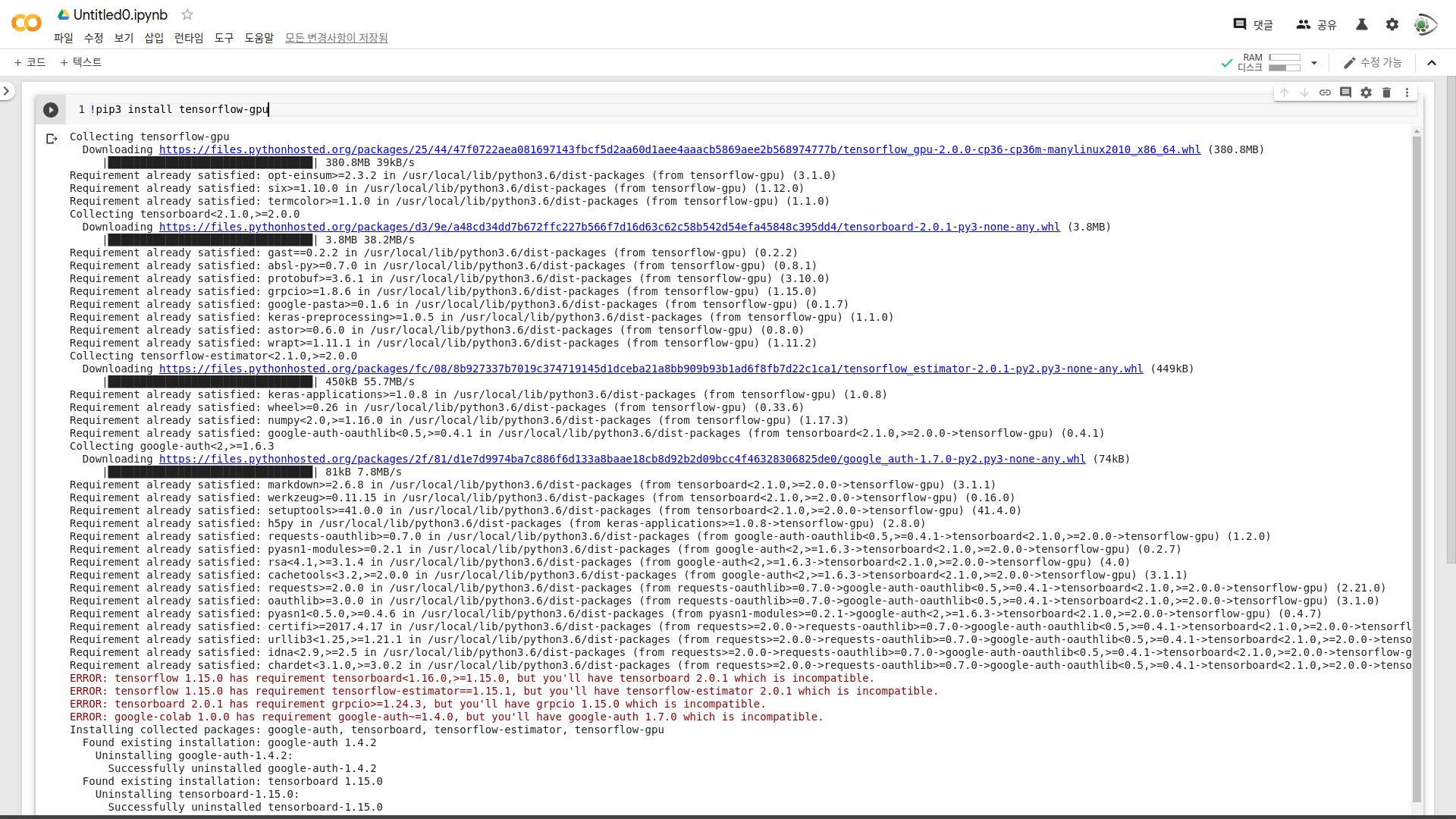
!pip3 install tensorflow-gpu만약 여러분들이 TensorFlow를 설치하려고 한다면, Jupyter Notebook에서 한 줄을 추가해놓고, !를 앞에 붙인 다음 커맨드를 입력하면 OS의 커맨드를 실행할 수 있습니다.
Use Data
또 한 가지, 데이터를 분석하려면 외부에 있는 데이터를 사용하거나 내가 가지고 있는 데이터를 불러와야 합니다. 데이터베이스의 경우, 데이터베이스 서버를 JDBC나 ODBC를 통해서 연결하는 방법이 있겠지만 정적 파일(bin, csv 등)의 경우, 어떻게 불러올 수 있나요?
흔히 이런 경우, 웹 서버에 정적 파일을 업로드 하여 Python의 REST API 라이브러리를 이용해 가져오는 방법을 떠올릴텐데, 하지만 이렇게 되면 Colab 환경에서의 운영체제 경로를 사용하는 것이기 때문에 나중에 데이터를 불러오는 등의 상황이 되면 내가 어느 경로에 저장을 했는지 찾기가 어려워 지게 됩니다.
따라서 이럴 때는 구글 드라이브를 이용하는 방법을 사용해 봅시다. 구글 드라이브에 내가 분석하고자 하는 데이터를 업로드 해놓고, 이를 Google Colab API를 사용하여 불러오는 방법입니다.
from google.colab import driveGoogle Colab API에는 Google Drive 뿐만 아니라 Authentication 등의 여러가지 API를 제공합니다. 여기에서는 외부 데이터를 사용하는 방법에 대해 다루고자 하니, 그에 필요한 drive를 import를 하도록 하겠습니다.
drive.mount('/content/drive')그런 다음, 자신의 드라이브를 Colab 환경에 마운트를 합니다. 마운트 경로는 '/content/drive'를 사용하도록 하겠습니다.

자신의 드라이브를 마운트하기 위해 인증키를 입력하라는 메시지입니다. 파란색의 링크를 눌러, 인증키를 받으신 후, 받으신 인증키를 넣으면 아래와 같이 마운트가 완료됩니다.

그럼 이제 '/content/drive'가 자신의 구글 드라이브의 최상위가 되는 것입니다. 만약, 여러분들이 구글 드라이브 메인에서 폴더를 하나 생성해놓고, 그 내의 파일을 불러오고자 한다면, '/content/drive/[폴더 이름]/[파일 이름]'으로 불러오시면 됩니다.
Use GPU
자 지금까지 살펴본 바로는 이러한 환경을 아무런 비용도 지불하지 않고, 또 여러분들이 직접 리눅스나 Python을 설치하지 않고도 이런 환경이 만들어졌습니다.
그럼 GPU를 사용하려면 어떻게 해야할까요?

상단 왼쪽에 보면 런타임 메뉴가 있습니다. 거기에서는 현재 환경에 대한 런타임을 바꿀 수가 있는데, 거기에서 런타임 유형 변경을 클릭하면 GPU를 사용할 수 있습니다. 물론 Colab에서는 TPU도 지원하지만 여기서는 GPU를 사용해보도록 하겠습니다.

그러면 짜잔, 여러분들도 GPU 한 개를 할당받으셨습니다. 우리는 이 GPU를 가지고 여러 머신 러닝 연습을 해볼 수가 있습니다.
그런데, GPU 성능이....?!

Wow, 무려 다름 아닌 Tesla K80 1개를 주어주네요. 이런 걸 무료로 사용해볼 수가 있다니... 엄청 좋네요. 하지만 여기에도 약간의 제약은 존재합니다.
이 GPU는 한 번에 12시간 동안 사용할 수 있습니다. 따라서 복잡하고 큰 데이터 용량을 훈련하였는데, 하루가 지나면 도중에 멈추므로 훈련에 적절한 시간을 조절하는 것이 중요할 것 같네요.
하지만 한 번의 코드에서 12시간, 한 VM의 환경에서 12시간이니 연습 용도나 간단한 머신 러닝 모델을 구축하는 데는 큰 문제가 없습니다. 무엇보다도 K80이면 성능이 워낙 뛰어나니깐요.
마치며...
어떠신가요? 이러한 환경을 무료로 그것도 쉽고 편리하게 제공해주는 곳은 없을 것입니다.
저는 간단한 머신 러닝 모델을 테스트해보기 위해 현재 환경을 자주 사용 중에 있습니다. 다만 큰 데이터를 돌리거나 훈련 시간이 이틀 이상 소요되는 무거운 데이터들에는 적합하지 않습니다. 물론 코드를 어떻게 줬고, 데이터 전처리를 어떻게 하느냐에 따라 무거운 데이터도 해당 환경에서 돌려볼 수 있겠지만 말이죠.
혹시 지금 머신 러닝 환경 구축이 어려워 머신 러닝 공부를 망설이신다거나 성능 좋은 GPU 사용하기 가격 부담이 커서 머신 러닝을 공부하는 걸 꺼려하고 계신다면 이 환경을 사용하면서 공부해보시면 좋을 것 같습니다.
'Data Analysis > Machine Learning' 카테고리의 다른 글
| [LLM] Langchain으로 AI E2E 애플리케이션 개발해보기 (1) | 2023.08.27 |
|---|---|
| Virtualenv를 사용한 Tensorflow 설치 (2) | 2017.06.29 |
